
The Bug That Hid From Every Tool Cloudflare Had
Cloudflare found a race condition buried in one of Rust's most-deployed libraries, and the fix was four lines

A quick update before we get into it.
Last year, 230 of you took a survey about a tool to keep your system design knowledge sharp using real case studies like the ones we cover here, and to actually help with interview prep without being just another basic boring interview prep app.
We heard you. 84% of you said you’d be interested in early access. It’s almost ready!
We’re opening early access soon, and founding members get 50% off locked-in pricing for life. If you want in, respond with Yes on the poll below. Two seconds, no commitment yet.
More updates to come soon!
Hyper runs underneath half the Rust web ecosystem. reqwest, axum, most production Rust services that speak HTTP all sit on top of it. This wasn’t a bug in Cloudflare’s code. It was a bug in the library itself, present for years across multiple major versions, and it took a kernel-level trace to even see it happening. If you run Rust in production, you’re probably running hyper. Read this one before it finds you.
TLDR
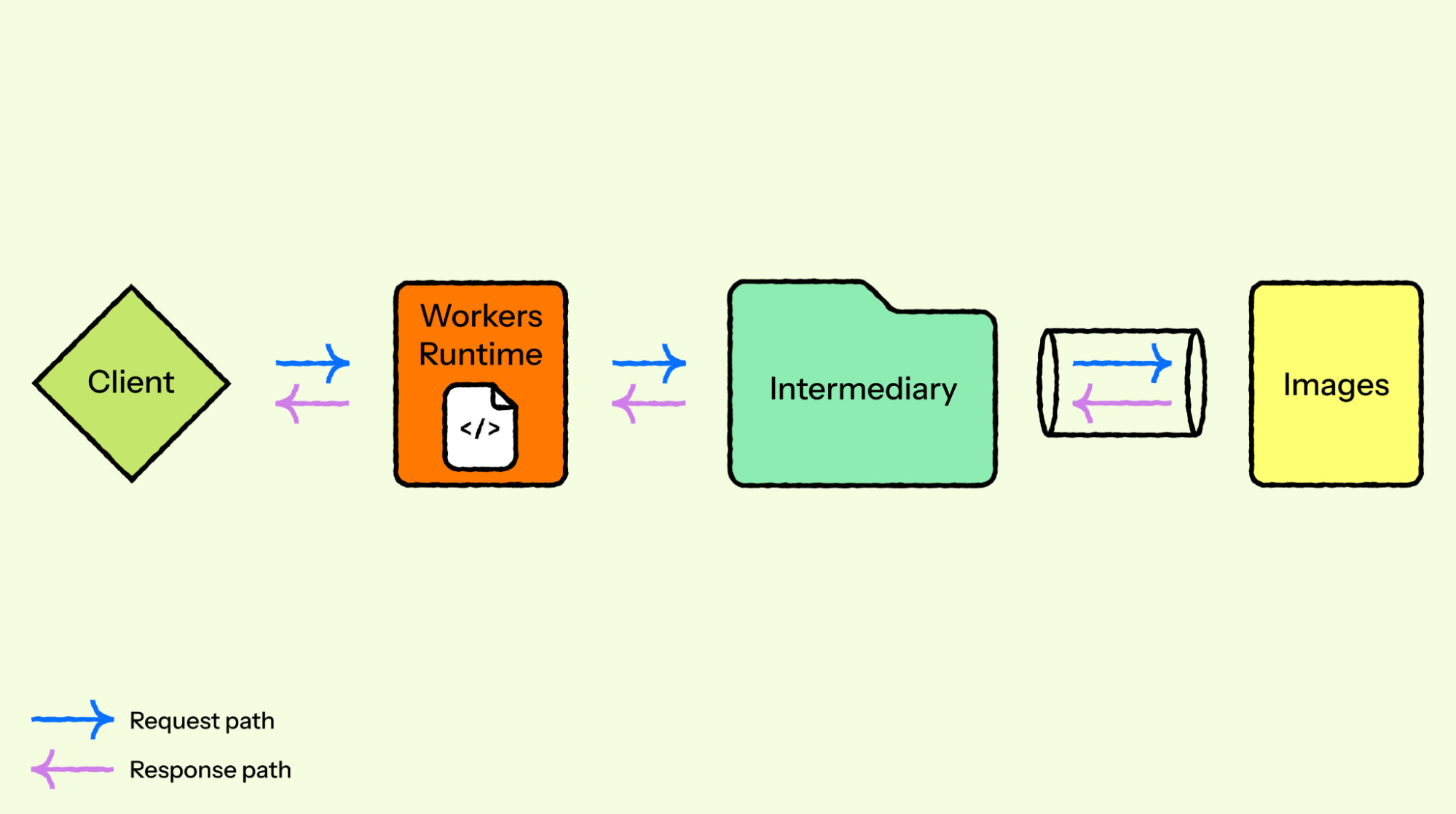
Cloudflare’s Images service started silently truncating large image responses. HTTP 200, correct Content-Length header, but only a fraction of the bytes actually arrived. No errors, no crashes. Six weeks of investigation later, the cause turned out to be four lines deep inside hyper’s connection lifecycle: a let _ = poll_flush(cx) that discarded a “still pending” signal and let the connection shut down before the buffer had actually drained.
The Bug That Doesn’t Show Up Anywhere You’d Look
A customer reported broken images coming back from a nested pipeline: an Images binding call feeding into a URL-based transformation. The outer layer logged “error reading a body from connection: end of file before message length reached”. The inner layer, the one actually producing the truncated response, logged nothing wrong at all. It returned 200. Its own service-level tracing said the response was sent.
Every observability tool Cloudflare had agreed nothing was wrong.
The bug lived below the layer those tools were watching. This is the same failure mode that took down GitHub for 24 hours after a 43-second network blip: the system insists everything is fine right up until a customer shows you it isn’t, and the gap between those two things is exactly where the real cause is hiding.
Why It Was Almost Impossible to Reproduce
The failure scaled with response size, only showed up in production under real concurrency, and vanished the moment they tested with curl. Each of those facts ruled something out. Curl never triggered it because curl reads as fast as data arrives, so the socket buffer never filled and the bug’s precondition never occurred. Local integration tests had the same problem. Even strace made the bug disappear when the filter was too broad, because the syscall interception overhead shifted the exact timing window the race needed.
The act of observing the system closely enough to debug it was fast enough to mask the bug. They had to narrow the strace filter to the minimum necessary syscalls to keep the timing intact. Any time you’re chasing a timing-dependent bug, the tool you reach for to see the problem can change the problem’s behavior.
The Actual Mechanism
Hyper’s connection lifecycle runs a loop in dispatch.rs that reads, writes, flushes, and decides whether to shut down. The relevant line:
let _ = self.poll_flush(cx)?;In Rust, let _ = expr discards the result, including Poll::Pending, the signal meaning “this isn’t done yet.” So when a response was fully encoded and handed to hyper as one in-memory block, hyper marked the write complete the moment encoding finished, not when the data actually left the buffer. If the socket accepted the first chunk and then blocked, because the reader downstream was a few milliseconds slower than usual, hyper discarded the pending signal, saw no more reads coming, and called shutdown() on the socket with megabytes of unflushed data still sitting in its buffer.
The trigger condition wasn’t a bug Cloudflare introduced. It had been sitting in hyper for years, across every version they tested. What changed was the reader on the other end of the socket. Cloudflare had recently replaced FL, their old request-routing intermediary, with a direct Unix socket connection for performance. The old reader happened to drain fast enough that the buffer almost never filled. The new, faster path occasionally let the buffer fill during large responses, exactly the condition the latent bug needed. An optimization made everything faster, and that speed is what exposed the flaw. It’s the same dynamic Uber ran into when they moved Distcp’s Copy Listing off a shared HDFS client: the fix that removed one bottleneck just shifted load onto a contention point nobody had stress-tested at the new speed.
The Fix, and Why the First Fix Was the Wrong One
The first patch added a pending check directly in the dispatch loop: if flush wasn’t done, return Poll::Pending and let the async runtime retry later. It worked. But it wasn’t the right fix to ship upstream. Returning pending early in the loop could starve reads on the same connection, and it breaks correctness for keepalive connections that reuse a socket across multiple requests.
The fix that landed moved one level deeper, into poll_shutdown itself:
rust
pub(crate) fn poll_shutdown(
&mut self,
cx: &mut Context<'_>,
) -> Poll<io::Result<()>> {
ready!(self.poll_flush(cx)?);
Pin::new(&mut self.io).poll_shutdown(cx)
}Flush before shutting down, every time. It doesn’t touch the dispatch loop’s behavior at all, it just closes the gap where the invariant was missing: the socket can’t close while there’s still unflushed data behind it. Cloudflare merged this into hyper upstream as PR #4018.
What to Take Back to Your System
Discarded results are where bugs hide. let _ = expr, or its equivalent in any language (ignored return values, swallowed exceptions, _ = err), throws away exactly the information you need when something stalls instead of completing. Audit the places in your codebase where you discard a result because it “usually doesn’t matter.” Usually isn’t always.
Application-level observability has a floor. Logs, traces, and metrics describe what your code thinks happened. They can’t see what the kernel or runtime did underneath. When every high-level signal says “fine” but users see broken output, drop a layer: strace, tcpdump, or whatever the equivalent is for your stack.
The tool you use to observe a race can erase it. If adding instrumentation makes a bug disappear, that’s not a fix, it’s a clue. Narrow your filter to the minimum needed, the way Cloudflare narrowed their strace syscall list, instead of assuming the bug is gone.
Making something faster can surface bugs that slowness was hiding. The race condition existed in hyper for years. It needed backpressure to trigger, and the older, slower intermediary happened to provide just enough resistance to avoid it. When you ship a performance win, ask what timing assumptions it just changed, not just what it sped up.
A four-line fix can take six weeks to find. The size of a fix tells you nothing about the size of the investigation behind it. Budget debugging time on signal strength (timing-dependent, scales with load, vanishes under direct testing), not on a guess about how hard the eventual fix will be.