
How Slack Keeps a Team of AI Agents from Losing the Plot
Inside the three-channel context system behind their security investigations

TLDR
Hundreds of inference calls per investigation. Megabytes of agent output. A team of LLMs all working on the same alert, none of them sharing memory by default. That’s what Slack’s security investigation service has to wrangle every time an alert fires.
The agents don’t share a brain. The API is stateless. Stuff every transcript into every prompt and you blow the context window. Strip too much out and the agents drift, contradict each other, and stop sounding like a team.
Slack’s answer: stop pretending one shared context can do the job. Build three of them. Each agent reads the channel that fits its role.
It’s one of the cleanest examples I’ve seen of context engineering as a real discipline, not a vibe.
The setup
Slack runs security investigations with a team of agents. A Director orchestrates. A bunch of Experts go gather evidence using domain-specific tools. A Critic reviews what the Experts produced and flags the bits that don’t hold up.
Investigations move through phases. Each phase has rounds. There’s no fixed budget, the Director decides when to stop.
The dependency runs both ways. Each agent needs enough of the wider investigation to stay coherent with the team. But shove the full transcript into every prompt and two things happen: you hit the context window, and the agent starts drifting toward whatever the loudest voice in the history said. Confirmation bias dressed up as continuity.
Same problem every multi-agent system hits. They built three context channels to solve it.
Channel one: the Director’s Journal
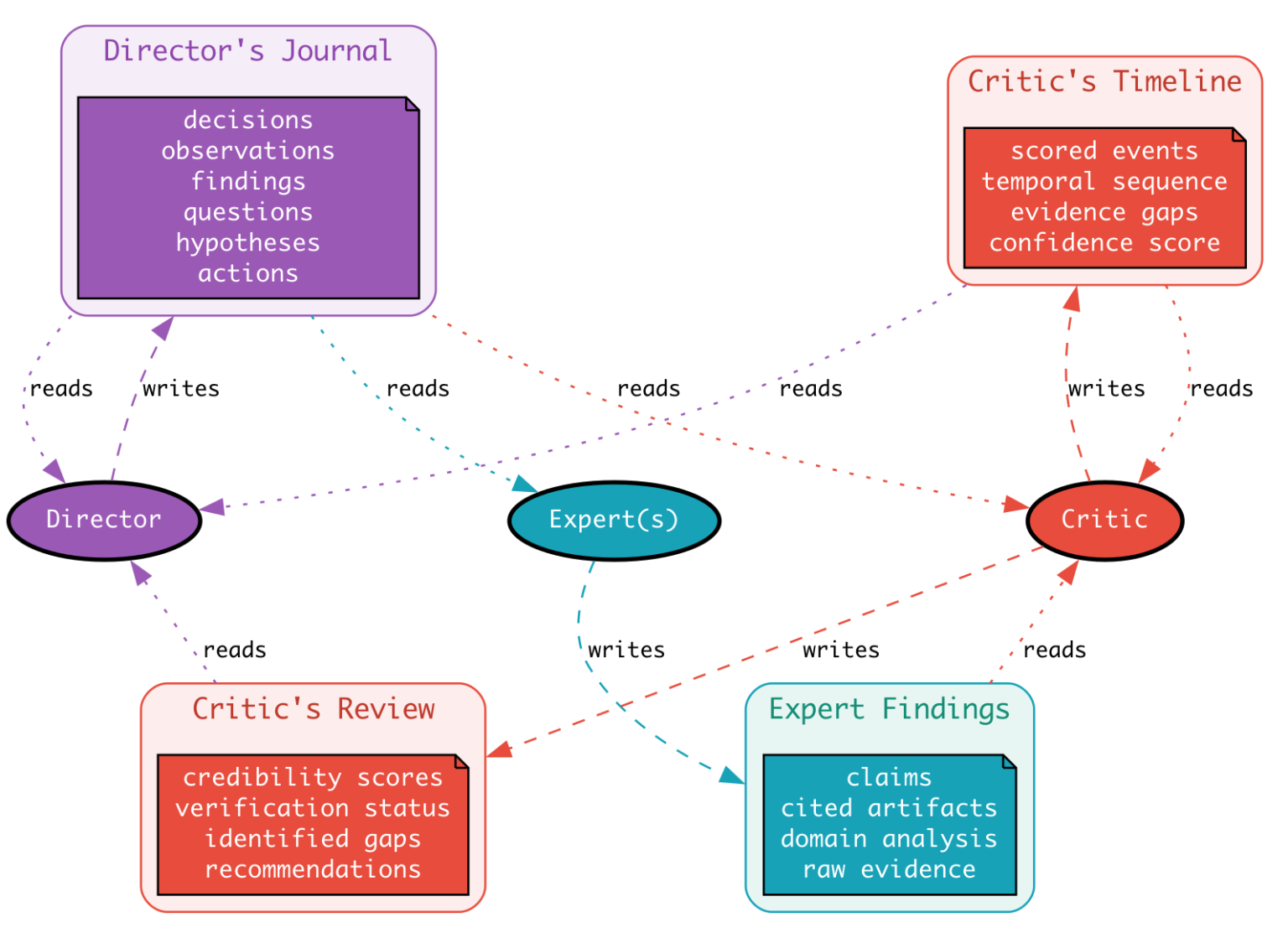
The Director keeps a journal. Not a chat log, but a structured one. Six entry types: decision, observation, finding, question, action, hypothesis. Every entry gets a phase, a round, a timestamp, a priority, and optional citations to evidence.
The journaling tool itself is dumb. It appends. The intelligence is in the prompt that tells the Director to use it constantly, and in the schema that forces every thought into a slot.
The Journal goes into every other agent’s prompt. It’s the spine. The Experts read it to understand what they’re being asked and why. The Critic reads it to understand what the Director was trying to prove.
Read enough Journal entries and you can watch the investigation think. One example from a real run: the Director starts by classifying an alert as a kernel module load, lists 4 expert domains it’ll need, notices the cgroup suggests a personal workstation, then realizes the alert is matching the path of a hook script rather than an actual modprobe call. By round five it’s preliminary-false-positive. By round seven it’s confirmed FALSE POSITIVE with all four Experts agreeing.
That progression is only legible because the Journal exists. Without it, you’d have a pile of disconnected expert outputs and no narrative.
This is the same shape of problem covered in a previous edition on designing AI agents that think in real time, different domain, but the structural answer is identical: give the orchestrator a working memory that everyone else can read.
